
VegaFusion 1.1#
DuckDB and Polars support, Altair 5 compatibility, and lots of bug fixes
By: Jon Mease
The VegaFusion team is happy to announce the release of version 1.1. In addition to the usual slew of bug fixes, this release includes support for evaluating Vega transforms in DuckDB, support for Polars and the DataFrame Interchange Protocol, and forward compatibility with the coming release of Altair 5.
DuckDB support#
DuckDB is an in-process SQL OLAP query engine and database that provides bindings for a wide variety of languages, including Python. The VegaFusion 1.1 Python library now includes two forms of integration with DuckDB. First, it can use DuckDB in place of DataFusion to power Vega transforms over the pandas DataFrames that are referenced by Altair charts. Second, VegaFusion 1.1 makes it possible to reference externally defined DuckDB tables and views in Altair charts.
Vega transforms with DuckDB#
VegaFusion can now be configured to evaluate Vega transforms using the DuckDB Python library by calling vegafusion.runtime.set_connection("duckdb").
Once the DuckDB connection is enabled, pandas DataFrames referenced by Altair charts are automatically registered with DuckDB and Vega transforms are translated into DuckDB SQL queries. Here is a full example, adapted from the 2D Histogram Heatmap Altair gallery example.
import vegafusion as vf
import pandas as pd
import altair as alt
# Configure DuckDB connection
vf.runtime.set_connection("duckdb")
# Enable Mime Renderer
vf.enable()
# Load 201k row version of the Vega movies dataset with pandas
movies = pd.read_parquet(
"https://vegafusion-datasets.s3.amazonaws.com/vega/movies_201k.parquet"
)
# Create an Altair chart from the pandas DataFrame as usual.
# Binning and aggregation will be evaluated against the DataFrame with DuckDB
chart = alt.Chart(movies).mark_rect().encode(
alt.X('IMDB_Rating:Q', bin=alt.Bin(maxbins=60)),
alt.Y('Rotten_Tomatoes_Rating:Q', bin=alt.Bin(maxbins=40)),
alt.Color('count():Q', scale=alt.Scale(scheme='greenblue'))
)
chart

Additionally, the transformed data can be extracted as usual:
vf.transformed_data(chart, row_limit=5).T
0 |
1 |
2 |
3 |
4 |
|
|---|---|---|---|---|---|
bin_maxbins_60_IMDB_Rating |
3.4 |
5.8 |
7 |
7 |
7.4 |
bin_maxbins_60_IMDB_Rating_end |
3.6 |
6 |
7.2 |
7.2 |
7.6 |
bin_maxbins_40_Rotten_Tomatoes_Rating |
60 |
25 |
85 |
80 |
80 |
bin_maxbins_40_Rotten_Tomatoes_Rating_end |
65 |
30 |
90 |
85 |
85 |
__count |
63 |
441 |
504 |
1260 |
1134 |
The default DataFusion connection can be re-enabled by calling vegafusion.runtime.set_connection("datafusion")
Performance benefit#
DuckDB has the ability to perform queries against Pandas DataFrames without first serializing them to Arrow. This can result in 10x+ speedups when visualizing large Pandas DataFrames with the VegaFusion Mime Renderer. Presently, the VegaFusion Widget Renderer always serializes DataFrames to Arrow and writes them to disk, so significant performance gains are not expected for the Widget Renderer.
Access DuckDB tables#
VegaFusion 1.1 also supports integration with external DuckDB connections, making it possible to reference DuckDB tables and views from Altair charts. To begin, import duckdb and create a new connection.
import duckdb
conn = duckdb.connect()
Pass this DuckDB connection to vegafusion.runtime.set_connection (instead of the string "duckdb" as in the previous example).
vf.runtime.set_connection(conn)
Next, use the DuckDB connection to create a table or view. Here, the DuckDB read_parquet method is used to load the 201k row movies dataset, and a DuckDB query is used to filter NULL values. The result of this query is registered as a table named movies.
relation = conn.read_parquet(
"https://vegafusion-datasets.s3.amazonaws.com/vega/movies_201k.parquet"
)
relation.query("tbl", """
SELECT * FROM tbl
WHERE Rotten_Tomatoes_Rating IS NOT NULL AND Imdb_Rating IS NOT NULL
""").to_table("movies")
DuckDB tables and views registered with conn may be referenced from Altair charts with a special URL syntax using table:// as the prefix. To reference the DuckDB table named movies, the Altair chart should be passed the url string "table://movies". Here is a full example
import duckdb
import vegafusion as vf
import pandas as pd
import altair as alt
# Create DuckDB connection
conn = duckdb.connect()
# Pass DuckDB connection to VegaFusion's set_connection method
vf.runtime.set_connection(conn)
# Enable Mime Renderer
vf.enable()
# Read parquet file using the DuckDB connection
relation = conn.read_parquet(
"https://vegafusion-datasets.s3.amazonaws.com/vega/movies_201k.parquet"
)
# Filter NULL values and register the result as a table named "movies"
relation.query("tbl", """
SELECT * FROM tbl
WHERE Rotten_Tomatoes_Rating IS NOT NULL AND Imdb_Rating IS NOT NULL
""").to_table("movies")
# Create an Altair chart that references the registered DuckDB table
chart = alt.Chart("table://movies").mark_rect().encode(
alt.X('IMDB_Rating:Q', bin=alt.Bin(maxbins=60)),
alt.Y('Rotten_Tomatoes_Rating:Q', bin=alt.Bin(maxbins=40)),
alt.Color('count():Q', scale=alt.Scale(scheme='greenblue'))
)
chart
See the DuckDB connection docs for more information.
Polars support#
Polars describes itself as a “Lightning-fast DataFrame library for Rust and Python”. Polars has quickly gained popularity as a faster alternative to pandas that also supports larger datasets.
VegaFusion’s new Polars integration makes it possible to input and output Polars DataFrames without conversion through pandas.
Polars as Input#
Here is a full example that uses Polars to read the 201k row movies dataset from a remote parquet file. The DataFrame’s filter method is then used to remove rows with NULL movie rating values. This filtered DataFrame is passed as the input to an Altair chart.
import polars as pl
import vegafusion as vf
import altair as alt
# Enable Mime Renderer
vf.enable()
# Load 201k movies parquet dataset
source = pl.read_parquet(
"https://vegafusion-datasets.s3.amazonaws.com/vega/movies_201k.parquet"
)
# Fitler out rows with null ratings
source = source.filter(
pl.col("IMDB_Rating").is_not_null() & pl.col("Rotten_Tomatoes_Rating").is_not_null()
)
# Create chart
chart = alt.Chart(source).mark_circle().encode(
alt.X('IMDB_Rating:Q', bin=True),
alt.Y('Rotten_Tomatoes_Rating:Q', bin=True),
size='count()'
)
chart
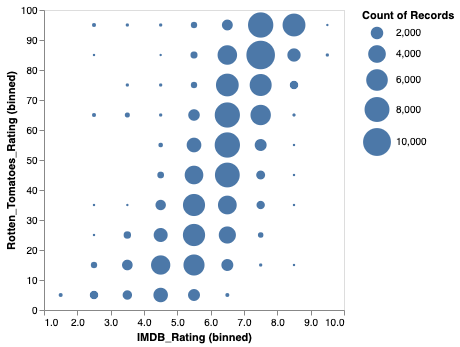
Polars as Output#
When a Chart that references a Polars DataFrame is passed to vegafusion.transformed_data, the result will also be a Polars DataFrame. Here is a Polars version of the example from the Transformed Data section.
import altair as alt
import vegafusion as vf
import polars a pl
# Enable mime renderer
vf.enable()
# Load 201k movies parquet dataset with Polars
source = pl.read_parquet(
"https://vegafusion-datasets.s3.amazonaws.com/vega/movies_201k.parquet"
)
# Build chart
chart = (
alt.Chart(source)
.transform_aggregate(
aggregate_gross='mean(Worldwide_Gross)',
groupby=["Director"],
).transform_window(
rank='row_number()',
sort=[alt.SortField("aggregate_gross", order="descending")],
).transform_calculate(
ranked_director="datum.rank < 10 ? datum.Director : 'All Others'"
).mark_bar().encode(
x=alt.X("aggregate_gross:Q", aggregate="mean", title=None),
y=alt.Y(
"ranked_director:N",
sort=alt.Sort(op="mean", field="aggregate_gross", order="descending"),
title=None,
),
)
).properties(
title="Top Directors by Average Worldwide Gross",
)
chart
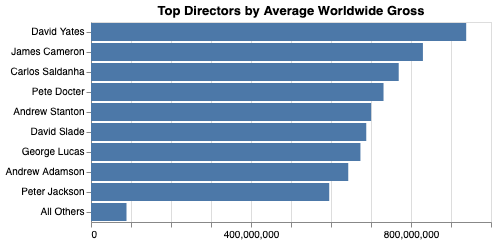
Now retrieve the chart’s transformed data as a Polars DataFrame.
transformed = vf.transformed_data(chart)
print(type(transformed))
transformed
<class 'polars.internals.dataframe.frame.DataFrame'>
shape: (10, 2)
ranked_director (str) |
mean_aggregate_gross (f64) |
|---|---|
David Yates |
9.37984e+08 |
James Cameron |
8.29781e+08 |
Carlos Saldanha |
7.69293e+08 |
Pete Docter |
7.31305e+08 |
Andrew Stanton |
7.00319e+08 |
David Slade |
6.88155e+08 |
George Lucas |
6.73577e+08 |
Andrew Adamson |
6.43134e+08 |
Peter Jackson |
5.95566e+08 |
All Others |
8.87602e+07 |
See the Polars Integration docs for more information.
DataFrame Interchange Protocol#
The “Polars as Input” workflow above is powered by a more general abstraction: The DataFrame Interchange Protocol. Along with Altair 5, VegaFusion 1.1 adds support for inputting any DataFrame object that supports this protocol including pyarrow Tables, Vaex DataFrames, cuDF DataFrames, and more.
Altair 5 Compatibility#
Along with Altair 5.0.0rc1, VegaFusion 1.1 updates Vega-Lite from 4.17.0 to 5.6.1. This is a significant update that enables many new features for Altair users. For more info, see the Altair 5 docs.
Learn more#
Check out these resources if you’d like to learn more: