Technology
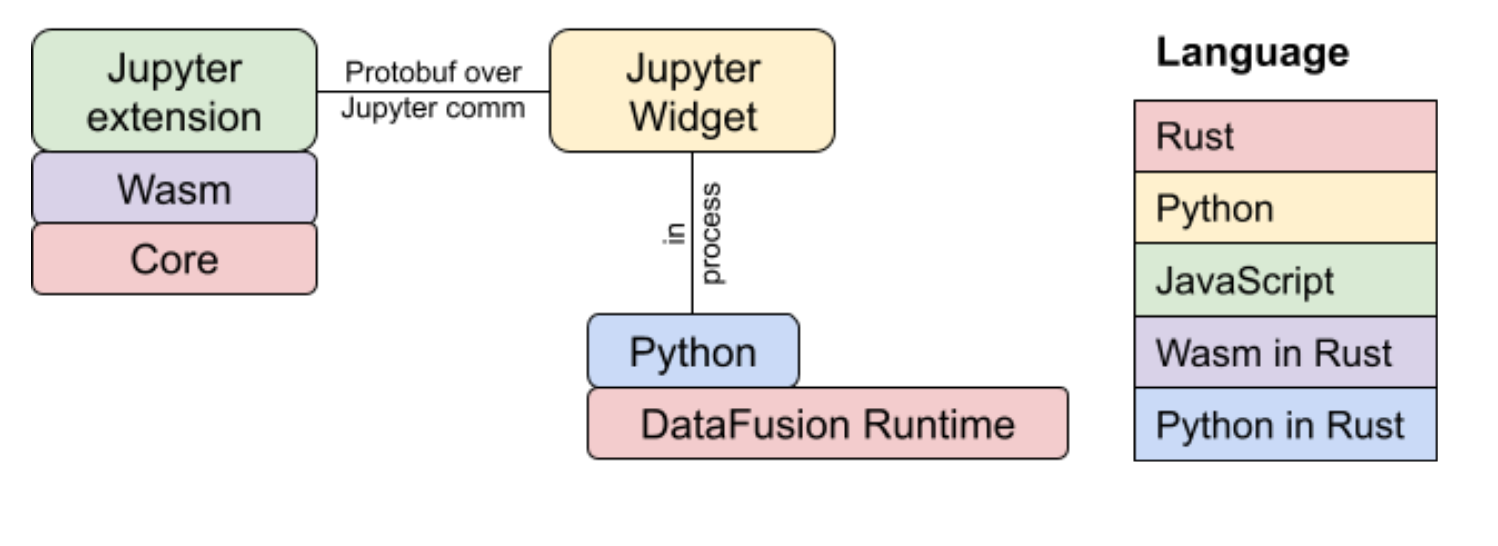
VegaFusion Technology Stack
VegaFusion uses a fairly diverse technology stack. The planner and runtime are both implemented in Rust.
In the context of vegafusion-jupyter, both the Planner and the client portion of the Runtime are compiled to WebAssembly using wasm-pack and wrapped in a TypeScript API using wasm-bindgen. This TypeScript API is used to integrate the WebAssembly library into the VegaFusion Jupyter Widget.
The server portion of the Runtime is wrapped in a Python API using PyO3, resulting in the vegafusion-python-embed package. The vegafusion package is used to integrate vegafusion-python-embed with Altair and the Python portion of VegaFusion Jupyter Widget.
The Task Graph specifications are defined as protocol buffer messages. The prost library is used to generate Rust data structures from these protocol buffer messages. When Arrow tables appear as task graph root values, they are serialized inside the protocol buffer specification using the Apache Arrow IPC format. The binary representation of the task graph protocol buffer message is what is transferred across the Jupyter Comms protocol.
DataFusion integration
Apache Arrow DataFusion is an SQL compatible query engine that integrates with the Rust implementation of Apache Arrow. VegaFusion uses DataFusion to implement many of the Vega transforms, and it compiles the Vega expression language directly into the DataFusion expression language. In addition to being really fast, a particularly powerful characteristic of DataFusion is that it provides many interfaces that can be extended with custom Rust logic. For example, VegaFusion defines many custom UDFs that are designed to implement the precise semantics of the Vega expression language and the Vega expression functions.